In tactical operations, reliable communication can mean the difference between mission success and failure. Traditional systems fail when network connections are lost—exactly when warfighters need information most. Raft Data Platform solves this critical problem using a novel approach inspired by how rumors spread in a small town.
Just as gossip spreads person-to-person without needing a central phone operator, Raft Data Platform uses “digital gossip” to keep data flowing even when network connections break. Each system continuously shares what it knows with its neighbors, ensuring that vital information reaches every connected device, regardless of network disruptions.
This technology enables commanders to maintain situational awareness across distributed forces, from enterprise command centers to forward operating bases. When network segments become isolated, each maintains a complete picture of available resources and automatically reconnects when communications are restored. The result: uninterrupted access to mission-critical data, enhanced operational resilience, and improved decision-making capability in the most challenging environments.
The Challenge: When Networks Fail, Missions Don’t Stop
In tactical environments, disconnection isn’t a bug—it’s the norm. Raft Data Platform designed to thrive under these conditions, using a gossip-based topology system that doesn’t just survive chaos—it uses it. Legacy systems crumble when a network link breaks. Raft’s gossip-powered monitoring adapts, syncs, and informs.
Why Legacy Monitoring Breaks Down
Monitoring distributed systems becomes significantly complex when nodes operate across disconnected networks with intermittent connectivity. Raft Data Platform’s nodes federate to form a distributed data platform, sharing data sources such as streaming feeds like GCCS, ADS-B, AIS, and batch feeds like FrOB and mission reports, across organizational and network boundaries. A typical federation might include enterprise nodes in cloud environments connected to edge nodes and headless systems at remote locations, all participating in a unified data fabric.
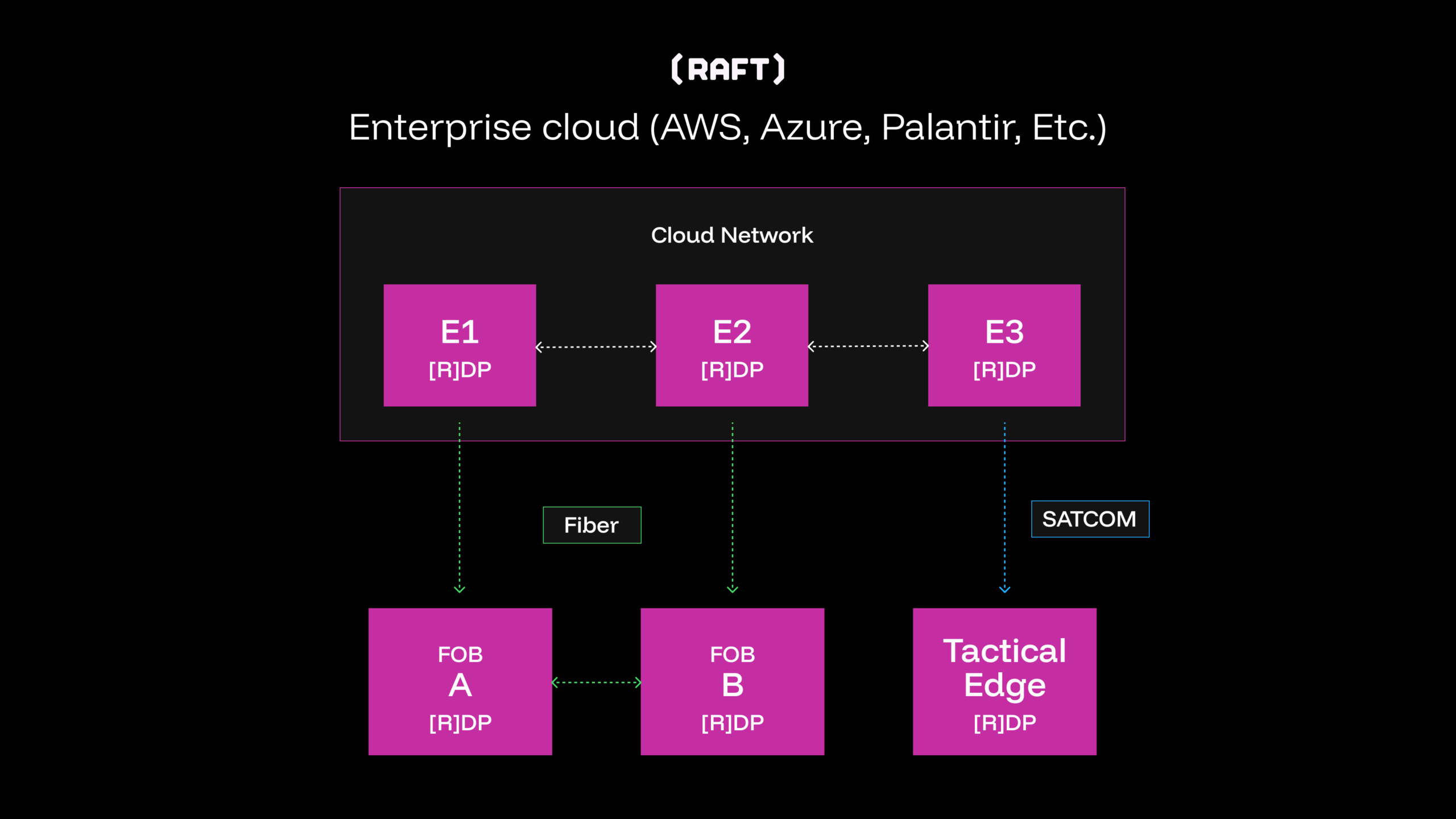
These federated nodes must maintain network awareness, operate during partitions, and reconcile when connectivity returns. Traditional centralized monitoring fails here, requiring constant connectivity to a central service. When network links fail in tactical environments, operators lose visibility into disconnected segments.
Our first attempt at solving this problem involved implementing basic health checks between federated nodes. Every few seconds, nodes would ping their peers to verify connectivity. This worked well enough when all nodes could reach each other but quickly broke down in real deployments. An operator connected to an enterprise node couldn’t see the status of edge nodes that were two or three hops away. Worse, when network partitions occurred, each side would mark the other as failed with no way to understand what was happening in the disconnected segment. We needed each node to maintain a complete view of the network topology, not just its immediate neighbors. This realization led us to implement a gossip-based topology discovery algorithm that piggybacks on those same health checks.
Gossip Protocols: Built to Survive Disconnection
Gossip protocols, also called epidemic protocols1, provide eventual consistency2 through peer-to-peer information exchange. Like their biological namesake, they spread information through a network without requiring central coordination.
A few key properties make gossip protocols suitable for distributed monitoring:
Eventual consistency: All nodes converge to the same view of the network.
Fault tolerance: Continues functioning despite node failures and network partitions.
Scalability: Communication overhead grows logarithmically with network size. Decentralization: No single point of failure or central coordinator.
These properties have made gossip protocols the foundation for many distributed systems, including Amazon DynamoDB3 and Apache Cassandra4.

How Raft Data Platform Works
Raft Data Platform’s gossip topology implementation piggybacks on existing health check mechanisms. Federated nodes already perform periodic health checks to peer nodes. We extend this mechanism to exchange topology information.
// Core gossip exchange during health checks.
func gossipWithPeer(peerURL string, localTopology *Topology) {
// Exchange topology with the peer.
response, err := exchangeTopology(peerURL, localTopology)
if err != nil {
// Mark peer as unhealthy if unreachable.
markPeerUnhealthy(peerURL)
return
}
// Track successful connection.
addConnectedNode(response.NodeID, peerURL)
// Merge the received topology.
mergeTopology(response.Topology)
}
func exchangeTopology(peerURL string, topology *Topology) (*ExchangeResponse, error) {
// Send our topology, receive peer's topology.
req := &ExchangeRequest{
NodeID: getLocalNodeID(),
Topology: topology,
}
return sendRequest(peerURL, req)
}Each node maintains its own complete view of the network topology. During gossip exchanges, nodes share their entire topology view, not just their local state. This enables transitive discovery: nodes learn about other nodes they cannot directly reach.
When Systems Disagree: Keeping Information Accurate
When nodes exchange topology information, conflicts may arise when different nodes have different views of the same node’s state. Raft Data Platform resolves these conflicts using timestamp-based precedence5:
// Merge incoming topology with local state.
func mergeTopology(local map[string]*Node, incoming *Topology) {
for _, incomingNode := range incoming.Nodes {
existingNode, exists := local[incomingNode.ID]
if exists {
// Compare timestamps to determine which information is newer.
if incomingNode.LastUpdated.After(existingNode.LastUpdated) {
// Update with newer information.
existingNode.Info = incomingNode.Info
existingNode.LastSeen = incomingNode.LastSeen
existingNode.LastUpdated = incomingNode.LastUpdated
}
} else {
// Add new node discovered through gossip.
local[incomingNode.ID] = incomingNode
}
}
} This approach ensures that newer information always takes precedence. Additionally, nodes never accept external updates about their own health status, avoiding confusion or malicious updates.
Staying Connected When Networks Break
Network partitions are inevitable in distributed systems, especially in tactical environments.
Raft Data Platform’s gossip topology handles partitions gracefully through several mechanisms.
Nodes track when they last communicated with peers. After some time without contact, a node is marked into an “unknown” state, preventing flip-flopping between connected and disconnected states during transient failures.
The system also identifies and removes orphaned nodes that have no bidirectional connections, preventing accumulation of stale entries:
// Check for orphaned nodes.
func removeOrphanedNodes(topology *Topology) {
incomingConnections := make(map[string]bool)
outgoingConnections := make(map[string]bool)
// Build connection maps.
for _, node := range topology.Nodes {
if len(node.ConnectedNodes) > 0 {
outgoingConnections[node.ID] = true
}
for _, connected := range node.ConnectedNodes {
incomingConnections[connected.ID] = true
}
}
// Remove orphaned nodes.
for _, node := range topology.Nodes {
hasIncoming := incomingConnections[node.ID]
hasOutgoing := outgoingConnections[node.ID]
if !hasIncoming && !hasOutgoing {
delete(topology.Nodes, node.ID)
}
}
} When a partition heals, nodes automatically exchange accumulated state changes. The merge process explained above ensures that all nodes eventually converge to a consistent view of the overall topology.
Operational Advantages
This gossip-based approach provides several key advantages for Raft Data Platform deployments:
- Complete visibility from any node: Connect to any accessible node to view the entire network topology, regardless of inter-node network constraints.
- Resilience during partitions: Each node maintains its own consistent view with automatic reconciliation in the event of network partitions.
- Zero additional infrastructure: The gossip approach piggybacks on RDP’s existing health check mechanisms without the need for new infrastructure or services.
Tech Considerations
Convergence time depends on gossip interval and network diameter. In a network of n nodes, convergence typically occurs within log(n) gossip rounds.
In practical terms: Information spreads surprisingly quickly. In a network of 1,000 systems, complete information sharing typically happens within about 10 communication rounds, taking just minutes rather than hours.
Additionally, message size grows linearly with network size since each exchange contains the full topology. Large deployments must consider compression, caching, and/or exchanging only topology deltas.
Scalability considerations: As networks grow larger, systems share more information during each exchange. For very large deployments, the system can be optimized to share only changes rather than complete network maps, similar to sending only news updates rather than entire newspapers.
Finally, security is critical. Nodes must reject external updates about their own state and validate all incoming topology information. Raft Data Platform uses cryptographic message signing (via JWT) to verify sender authenticity and prevent tampering.
Security in practice: Each system digitally signs its communications, like using an official military seal on orders. This prevents adversaries from injecting false information or impersonating legitimate systems.
This is Mission Tech
Raft Data Platform’s gossip-based topology provides the foundation for its distributed monitoring. Topology information provides a framework for advanced features like intelligent data routing based on network conditions, automatic failover, distributed query planning, and network-aware data replication strategies.
Additionally, when presented to operators, the topology view enables rapid troubleshooting of connectivity issues, identification of network bottlenecks, and informed decisions about resource allocation across the federated network.
By leveraging proven distributed systems principles, Raft Data Platform enables reliable operations in challenging environments where traditional approaches fail. Raft Data Platform’s gossip-based topology allows operators to maintain visibility and control across their entire federated data platform, regardless of network conditions. What started as a simple extension to health checks has become a foundational component, enabling Raft Data Platform to operate reliably at the tactical edge.
References
- Demers, A., Greene, D., Hauser, C., Irish, W., Larson, J., Shenker, S., Sturgis, H.,Swinehart, D., and Terry, D. (1987). “Epidemic Algorithms for Replicated Database Maintenance.” https://dl.acm.org/doi/10.1145/41840.41841
- Vogels, W. (2009). “Eventually Consistent.” https://dl.acm.org/doi/10.1145/1466443.1466448
- DeCandia, G., Hastorun, D., Jampani, M., Kakulapati, G., Lakshman, A., Pilchin, A.,Sivasubramanian, S., Vosshall, P., and Vogels, W. (2007). “Dynamo: Amazon’s Highly Available Key-value Store.” https://www.amazon.science/publications/dynamo-amazons-highly-available-key-value-store
- Lakshman, A. and Malik, P. (2010). “Cassandra: A Decentralized Structured Storage System.” https://dl.acm.org/doi/10.1145/1773912.1773922
- Lamport, L. (1978). “Time, Clocks, and the Ordering of Events in a Distributed System.” https://amturing.acm.org/p558-lamport.pdf

![Raft [R]DP Blog Post - Thumbnail Image](https://teamraft.com/wp-content/uploads/Raft-RDP-Blog-Post-Thumbnail-@2x.jpg)