
About a year ago, I wrote a blog post titled “Building a Distributed Data Platform for Scale “. Since then, Raft has been working on a Data Fabric. Early on in architecting the implementation of Data Fabric, we adpoted Trino as our query engine mechanism. Trino allows us to connect to multiple data sources and run queries against databases, without copying the data. Data exists in many places, and increasingly so. As the data becomes disparate, we need tooling that will enable joining data together, making insights possible. Without a unified abstraction layer, a data operator needs to run independent queries, using multiple interfaces. Trino takes on the work of maintaining the connection to the data source and allowing data operators to focus on the data logic.
Useful data can be anywhere. We can group the sources, based on their common properties. There are 3 main groups:
- Databases – Data that is organized, stored, and curated according to a specific structure and relation. MySQL, SQL Server, Postgres, Redis, etc.
- Streaming Data – Live, low latency data, coming in from a data source that is constantly emitting changes. Typically a sensor, or a data feed.
- Objects – Files, large payloads with a variety of file types and object stores.
With these 3 possible sources in mind, here is a high-level architect overview of a Trino-powered data query engine, powered by Trino might look like:
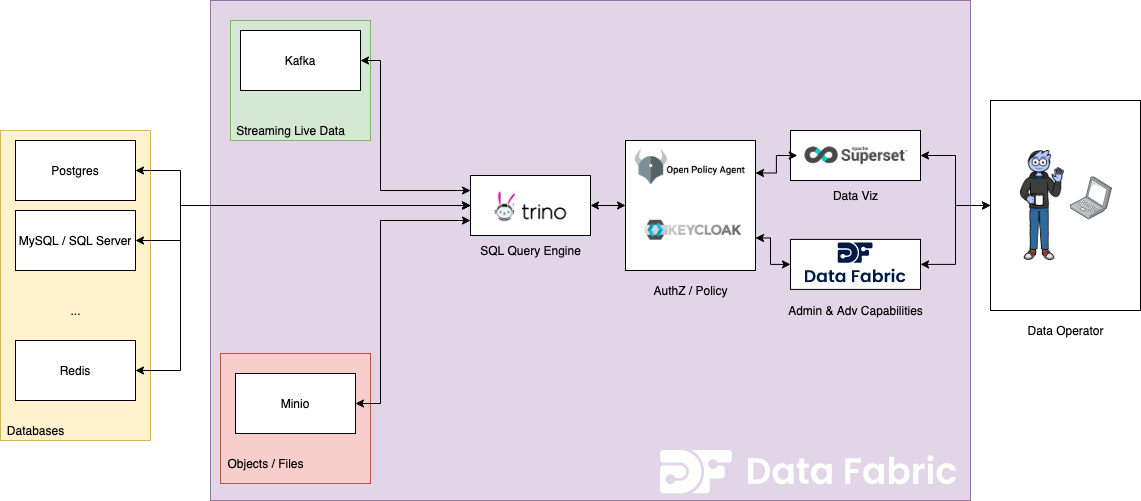
Trino comes with connectors to many common data sources. Since Trino is open source, adding new connectors is a possibility if needed. Trino has a plugin architecture, allowing integration with Open Policy Agent and Keyclaok for authentication and authorization. From there, we can connect a visualization or data analytics tool, ie. Superset or Tableau, to interact directly with Trino while maintaining strict data access controls. To the data operator, a lot of magic is happening behind the scenes.
Storytime
Did I get you fully confused yet? Let’s follow an example. Let’s assume that Rafty is our data operator. Rafty is a research student working on trying to predict when major flight disruptions will take place using AI/ML. How could he do it? Rafty is given access to the Data Fabric, with Trino at its core, and starts to add the data to Trino catalogs. First, he adds the flight status stream. The data may follow a schema such as:

Each message in this dataset is a single flight. The flights will be received by Kafka. As Rafty looks into the flight status, he notices that the data doesn’t include any geographic information, so he loads the Airport Codes data set into Postgres and connects Postgres to Trino. The data for the airports looks like this:
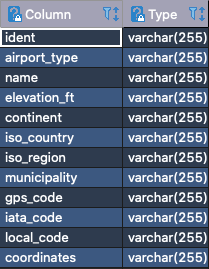
Now, Rafty can map each flight status to a geographic location. Rafty spends a long time thinking of more data sets that might be useful and decided to add the NOAA Climate Data Online to the mix. Now with a single query, Rafty can see all canceled flights, along with the geographic location and the live weather recorded at the location.
Using these data sources, lots of programming, math, and countless hours, Rafty should be able to come up with a model to predict flight cancelations with a high level of confidence.
Life without Trino
With Trino, Rafty’s life is easy, access to the data is fast, and Rafty can dedicate his time to more important tasks. Without Trino to do the heavy lifting of combining the data, Rafty would have to write code to talk to 3 different APIs. Then process the results, combine them and try to make sense of things. In this version of the story, Rafty will spend most of his time working on connecting to the data, and the least amount of time focused on business logic. Data operators should be allowed to focus on data and have the freedom to get insights from data. Having them focus on connecting to data is a waste of resources.
