
Where we are now
Machine learning (ML) is a field of inquiry devoted to understanding and building systems that “learn” – that is, systems that leverage data to improve performance on some set of tasks. It is seen as a part of artificial intelligence, as shown in the diagram below.
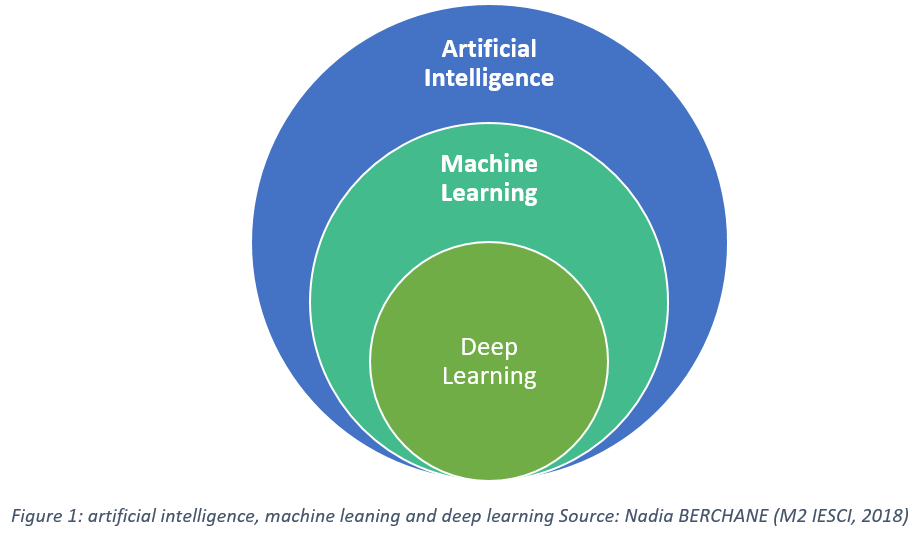
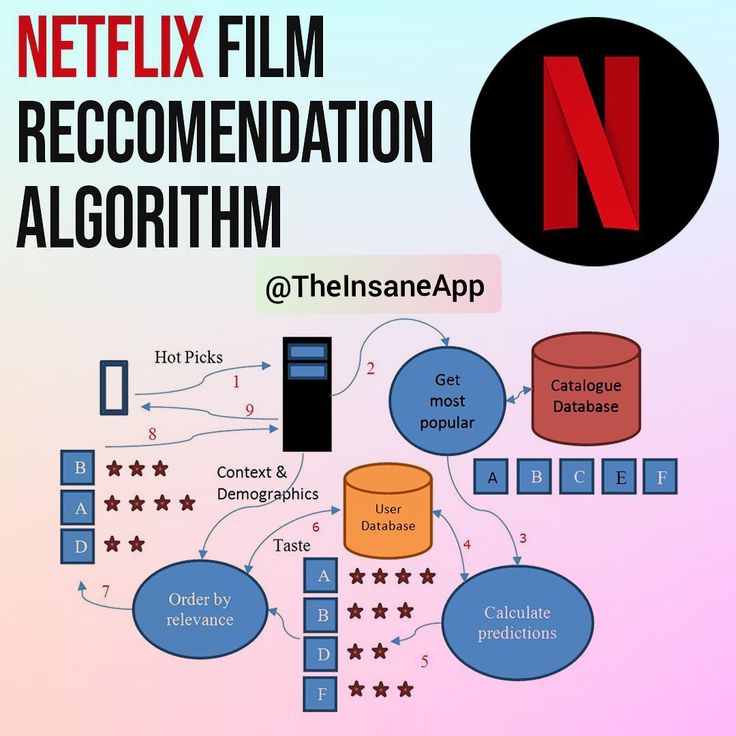
Machine Learning has really kicked off and we’ve seen impressive accomplishments in this field of research with the creation of models such as BERT, GPT, ChatGPT, and others. So this leads to the question: “What’s next and how do we productionize these ML models?” Some of the bigger tech companies have implemented ML pipelines using tools such as Spark and Apache Airflow, while others, such as the Netflix recommendation algorithm shown below, have created their own Machine Learning infrastructure.
Introducing Kubeflow
Today I’m going to walk you through using Kubeflow for such an infrastructure. So what exactly is Kubeflow? Well, Kubeflow is an open-source platform, introduced by Google, for machine learning and MLOps built on top of Kubernetes. The different stages in a typical machine learning lifecycle are represented with different software components in Kubeflow, including model development, model training, model serving, and automated machine learning.
So this is how I see kubeflow currently fitting into the ecosystem. This is specifically for Data Fabric since this is where this work has been mostly done at.
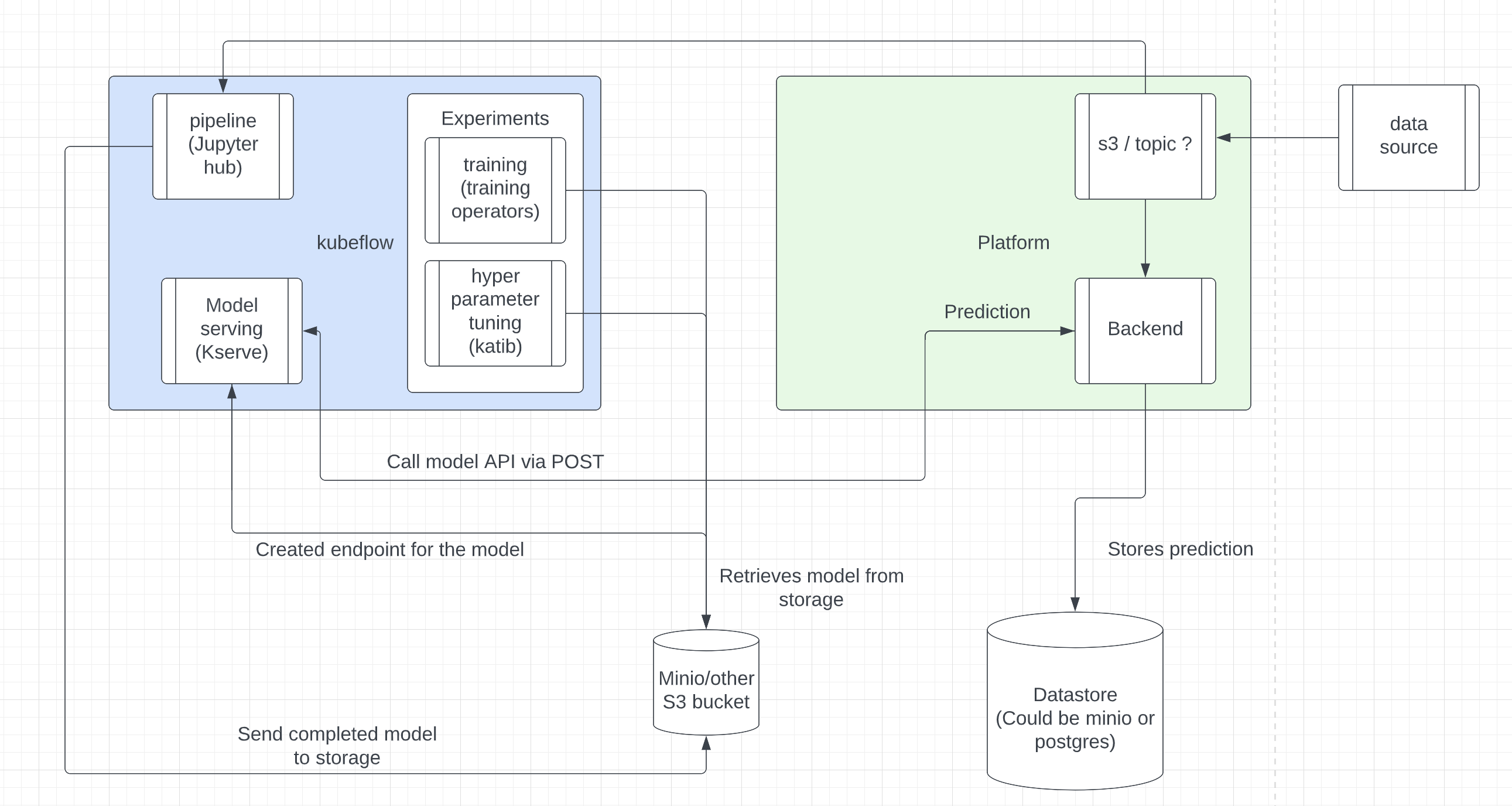
Here you can see the many different components of Kubeflow. The main components being the model training and model serving. I’ll run through these components here, along with example code and commands. The resources section below has the repository where you can download Kubeflow and start installing it.
Training the Model
Training pipeline can be done in a simple way. Here are some code examples of how to build a simple pipeline in Kubeflow.
!python3 -m pip install kfp==1.8.14 --upgrade --user
import kfp
import kfp.dsl as dsl
from kfp.v2.dsl import component, Input, Output, InputPath, OutputPath, Dataset, Metrics, Model, Artifact
@component(
packages_to_install = ["pandas", "sklearn"],
)
def load(data: Output[Dataset]):
import pandas as pd
from sklearn import datasets
dataset = datasets.load_iris()
df = pd.DataFrame(data=dataset.data, columns= ["Petal Length", "Petal Width", "Sepal Length", "Sepal Width"])
df.to_csv(data.path)
@component(
packages_to_install = ["pandas"],
)
def print_head(data: Input[Dataset]):
import pandas as pd
df = pd.read_csv(data.path)
print(df.head())
@dsl.pipeline(
name='Iris',
description='iris'
)
def pipeline():
load_task = load()
print_task = print_head(data=load_task.outputs["data"])
kfp.compiler.Compiler(mode=kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE).compile(
pipeline_func=pipeline,
package_path='iris_csv.yaml')
After running this cell you’ll get an iris_csv.yaml file and you can put that file into the training pipeline manually through the Kubeflow UI under the pipelines tab. Afterwards you’ll have to create an experiment and a run, then view the results of the run in the graph.
Serving the model
Serving the model is mostly done using kubectl commands. Additionally you’ll need to create a yaml file to point to where the model lives. Here are some snippets for creating a test service using the famous iris training dataset, as well as the results:
kubectl create namespace kserve-test
kubectl apply -n kserve-test -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
spec:
predictor:
model:
modelFormat:
name: sklearn
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model"
EOF
# Can put this into a .yaml file (example is sklearn.yaml)
kubectl get inferenceservices sklearn-iris -n kserve-test
kubectl get svc istio-ingressgateway -n istio-system
# GKE
export INGRESS_HOST=worker-node-address
# Minikube
export INGRESS_HOST=$(minikube ip)
# Other environment(On Prem)
export INGRESS_HOST=$(kubectl get po -l istio=ingressgateway -n istio-system -o jsonpath='{.items[0].status.hostIP}')
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
cat <<EOF > "./iris-input.json"
{
"instances": [
[6.8, 2.8, 4.8, 1.4],
[6.0, 3.4, 4.5, 1.6]
]
}
EOF
#Example request
SERVICE_HOSTNAME=$(kubectl get inferenceservice sklearn-iris -n kserve-test -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v -L -H "Host: ${SERVICE_HOSTNAME}" -H "Cookie: authservice_session=add_authservice_session_cookie_value_from_browser" http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/sklearn-iris:predict -d @./iris-input.json
The output of the request above should look like this:
* Trying 10.152.183.241...
* TCP_NODELAY set
* Connected to 10.152.183.241 (10.152.183.241) port 80 (#0)
> POST /v1/models/sklearn-iris:predict HTTP/1.1
> Host: sklearn-iris.admin.example.com
> User-Agent: curl/7.58.0
> Accept: */*
> Cookie: authservice_session=MTU4OTI5NDAzMHxOd3dBTkVveldFUlRWa3hJUVVKV1NrZE1WVWhCVmxSS05GRTFSMGhaVmtWR1JrUlhSRXRRUmtnMVRrTkpUekpOTTBOSFNGcElXRkU9fLgsofp8amFkZv4N4gnFUGjCePgaZPAU20ylfr8J-63T
> Content-Length: 76
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 76 out of 76 bytes
< HTTP/1.1 200 OK
< content-length: 23
< content-type: text/html; charset=UTF-8
< date: Tue, 12 May 2020 14:38:50 GMT
< server: istio-envoy
< x-envoy-upstream-service-time: 7307
<
* Connection #0 to host 10.152.183.241 left intact
{"predictions": [1, 1]}
Conclusion
Machine Learning has come a long way and the current state of ML is trending towards how to better productionize these Machine Learning models, with Kubeflow being one possible way of doing just that.
- Minikube: 1.22.0
- Kustomize: 3.2.0
- Kubernetes: 1.21.0
- Kubeflow manifests: 1.6.0 and 1.6.1
Resources
- https://github.com/kubeflow/manifests#installation
- https://kserve.github.io/website/0.7/get_started/first_isvc/#run-your-first-inferenceservice
- https://v1-5-branch.kubeflow.org/docs/components/pipelines/
- https://github.com/raft-tech/data-fabric/tree/dev/examples/Kubeflow
