
Data is everywhere and it is big. Every organization is constantly generating data, however not all of it is easily accessible to everyone that needs it. For example, over time organizations may establish new data stores. For some organizations, it is rather easy to mandate that all databases use the same technology and versions. For others, it’s not that easy. Large organizations that have been around for a while have accumulated databases and tech debt. This means that there are potentially lots of different technologies and versioning in play. Moving all the data to a central location or tech stack is feasible in some cases, but not in all cases. Sometimes it is better to leave the data where it is and use a distributed query engine rather than a centralized database. In this post, we will begin to lay the foundations needed for such a data platform that can scale up and serve the data needs of a large org with lots of data silos.
Setting up data silos
Before we can start, let’s setup some data sources to illustrate the problem. We will use public Airline on-time performance data from 2008. The data file for that year is about 700MB and contains over 7 million rows. We will load the data into a MongoDB NoSQL database. The data set is described as follows:

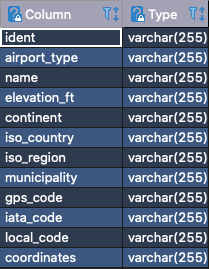
While looking at the data, you may notice that it doesn’t include any geographic information. There are airport codes for the Origin and Destination, but those are just airport codes. We need to use another to retrieve the location of the airport based on the airport code. The Airport Codes is another public data set that we will load into a PostgreSQL database. This data set is a bit smaller as you can imagine with around 12MB and 60,000 rows. The data has the following schema:
The problem space
We now have the problem at the core of this post. We have 2 data sets that can be joined via the airport code. Traditionally, we would export the data from the smaller database and create a mirror table of that data in the larger one, then run the query against a single database. As changes are made at the source we would have to be updated in the mirror. This doesn’t scale up very well when multiple sources and tables need to be kept in sync. Not to mention that data is duplicated. There has to be a better way.
Hello Presto
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.

Presto allows us to “bridge” multiple data sources and query the data using SQL. This means that we can connect our 2 data sources without copying the data using a common language. By the end of the post, we will be able to run a single query like the one bellow and get the results:
select d2008.origin, ad.name, count(*) as cnt
from mongodb.airline_data.data2008 as d2008
join postgresql.public.airport_codes as ad
on ad.local_code = d2008.origin
group by d2008.origin, ad.name
order by cnt desc
Visulation
It’s great that we can query data from multiple sources, but humans are visual and a graph or a chart can often speak louder than a table. Apache Superset is a lightweight data exploration and visualization platform. This will enable us to create stunning visual representations of large data sets in a blink of an eye.
One Docker Compose file to rule them all
Since this is the beginning of our journey, it’s always good to start with something that can run locally. Anything we run locally can be ported to Kubernetes and make its way to production. Here is the docker compose file we will be using:
version: '3.9'
x-superset-image: &superset-image apache/superset:latest-dev
x-superset-depends-on: &superset-depends-on
- db
- redis
x-superset-volumes: &superset-volumes
- ./docker:/app/docker
- superset_home:/app/superset_home
services:
postgres:
container_name: postgres_container
image: postgres
environment:
POSTGRES_USER: ${POSTGRES_USER:-postgres}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-changeme}
PGDATA: /data/postgres
volumes:
- postgres:/data/postgres
ports:
- "5432:5432"
networks:
- data_platform_demo
restart: unless-stopped
mongodb_container:
image: mongo
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: rootpassword
ports:
- 27017:27017
networks:
- data_platform_demo
volumes:
- mongodb_data_container:/data/mongodb
presto:
image: ahanaio/prestodb-sandbox
container_name: presto
volumes:
- presto:/usr/share/presto/data
expose:
- "8080"
ports:
- "8080:8080"
networks:
- data_platform_demo
db:
env_file: .env-non-dev
image: postgres:10
container_name: superset_db
restart: unless-stopped
volumes:
- db_home:/var/lib/postgresql/data
redis:
image: redis:latest
container_name: superset_cache
restart: unless-stopped
volumes:
- redis:/data
networks:
- data_platform_demo
superset:
env_file: .env-non-dev
image: *superset-image
container_name: superset_app
command: ["/app/docker/docker-bootstrap.sh", "app-gunicorn"]
user: "root"
restart: unless-stopped
ports:
- 8088:8088
depends_on: *superset-depends-on
volumes: *superset-volumes
networks:
- data_platform_demo
superset-init:
image: *superset-image
container_name: superset_init
command: ["/app/docker/docker-init.sh"]
env_file: .env-non-dev
depends_on: *superset-depends-on
user: "root"
volumes: *superset-volumes
networks:
- data_platform_demo
networks:
data_platform_demo:
driver: bridge
volumes:
postgres:
mongodb_data_container:
presto:
superset_home:
db_home:
redis:
The docker-compose up command will bring up a lot of services, so make sure your docker configuration has enough resources to run everything. Here is my local configuration, YMMV:

Once everything is running, the data can be loaded into the databases using
Adding the connectors to Presto
With Presto up and running, we need to create a configuration file for each connector inside the Presto container, etc/catalog/postgresql.properties and etc/catalog/mongodb.properties. The content for it is:
connector.name=postgresql
connection-url=jdbc:postgresql://host.docker.internal:5432/
connection-user=postgres
connection-password=changeme
and
connector.name=mongodb
mongodb.seeds=mongodb_container:27017
mongodb.credentials=root:rootpassword@admin
Once the configuration files are set, we can restart Presto with docker restart $(docker ps | grep presto | awk '{print $1}') and it will connect to each one of the data sources.
Connecting to Presto
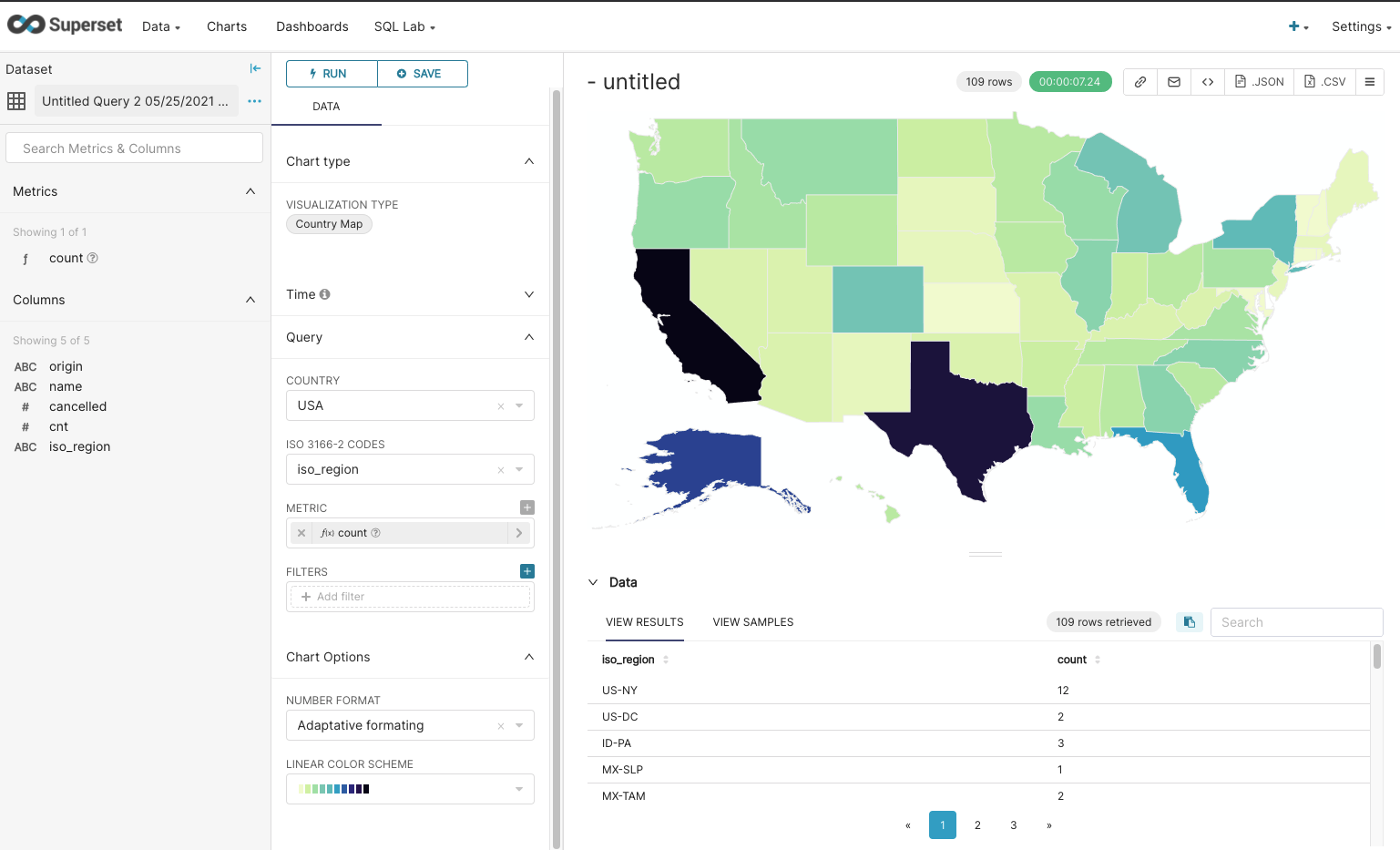
Presto is available via a JDBC connection and any client using localhost:8080. In our case, we are going to connect Superset as a UI and SQL editor. A few more clicks later and we have a geographical representation of flight data for 2008 by state, on a map.
Next steps
Introducing a query engine such as Presto is one of many steps towards building a data platform at scale. Presto enables the creation of a centralized access point and a standardized language (SQL) to access the data. From here, we can continue building the platform by adding features, such as real-time data streaming, security access controls, high availability and redundant deployment, and many more.
If you would like to know more about the awesome things we build at Raft, send us an email [email protected] or connect with us on LinkedIn.



![Raft [R]DP Blog Post - Thumbnail Image](https://teamraft.com/wp-content/uploads/Raft-RDP-Blog-Post-Thumbnail-@2x.jpg)

