This is a two-part blog series where we explain the intricacies of object detection, state-of-the-art research being done by the larger community, and applied theory by Raft.
What is Object Detection?
Object Detection is a common Computer Vision problem which deals with identifying and locating object of certain classes in the image. Interpreting the object localization can be done in various ways, including creating a bounding box around the object or marking every pixel in the image which contains the object (called segmentation).

How is it different from Image Classification ?
One of the most common misconceptions are the differences between image classification and object detection. Let’s start with understanding what is image classification.
Consider the below image:

You will instantly recognize this image. It’s a dog. Take a step back and analyze how you came to this conclusion. You were shown an image and you classified the class it belonged to (a dog, in this instance). And that, in a nutshell, is what Image Classification is all about.
As you saw, there’s only one object here: a dog. We can easily use image classification model and predict that there’s a dog in the given image. But what if we have both a cat and a dog in a single image?

In this instance we can train a multi-label classifier. Now, there’s another caveat – we won’t know the precise location (pixels) of either animal/object in the image.
That’s where Image Localization comes into the play. It helps us to identify the location of a single object in the given image. In case we have multiple objects present, we then rely on the concept of Object Detection. We can predict the location along with the class for each object using Object Detection.

Application of Object Detection
Object detection is breaking into a wide range of industries, with use cases ranging from personal security, air defense, to productivity in the workplace. Object detection and recognition is applied in many areas of computer vision, including image retrieval, security, surveillance, automated vehicle systems and machine inspection. The possibilities are endless when it comes to future use cases for object detection.
Lets discuss some current and future applications of Object Detection in detail.
Optical Character Recognition (OCR)
Optical character recognition or optical character reader, often abbreviated as OCR, is the mechanical or electronic conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image, we are extracting characters from the image or video.

Widely used as a form of information entry from printed paper data records – whether passport documents, invoices, bank statements, computerized receipts, business cards, mail, printouts of static-data, or any suitable documentation it is a common method of digitizing printed texts so that they can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes such as cognitive computing, machine translation, (extracted) text-to-speech.
Self-driving Cars
One of the best examples of object detection is autonomous driving and popularized by Tesla. In order for a car to decide whether toaccelerate, apply brakes, or turn, it needs to know where all the objects are around the car and what those objects are. This requires object detection and segmentation in real-time to detect pedestrians, cars, bicycles, etc.
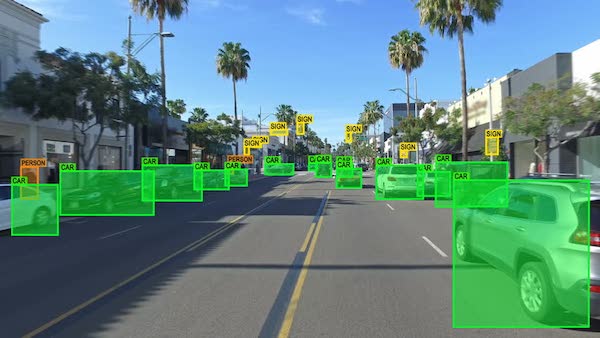
Object Tracking
Object detection system is also used in tracking the objects, for example tracking a ball during a football match, tracking a fast moving object in space, or tracking a person in a video.
![]()
Face Detection and Face Recognition
Face detection and Face Recognition is widely used in computer vision applications. We noticed how facebook detects our face when we upload a photo. This is a simple application of object detection that we see in our daily life. Face detection is a specific case of object-class detection. In object-class detection, the task is to find the locations and sizes of all objects in an image that belong to a given class. Examples include upper torsos, pedestrians, and cars.
Face recognition goes beyond face detection. It actually attempts to establish whose face it is. Face-detection algorithms focus on the detection of frontal human faces. It is analogous to image detection in which the image of a person is matched bit by bit. Image matches with the image stores in database. Any facial feature changes in the database will invalidate the matching process.

There are lots of applications of face recognition. Face recognition is already being used to unlock phones and specific applications. Face recognition is also used for biometric surveillance, Banks, retail stores, stadiums, airports and other facilities use facial recognition to reduce crime and prevent violence.
Different method of Object Detection
Traditional object detection
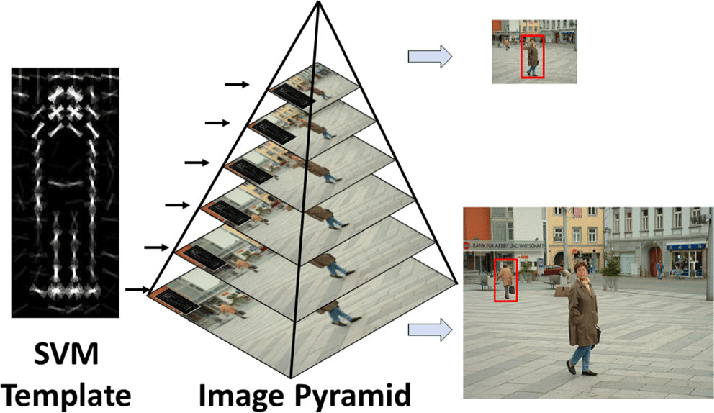
Object detection was studied even before the breakout popularity of Convolutional Neural Network (CNNs) in Computer Vision. Although we showed how to perform CNNs in another blog post it is worth taken a glance at the conventional methods used prior to CNN that lead to the inspiration of CNNs
Object detection before Deep Learning was a several step process, starting with edge detection and feature extraction using techniques like SIFT, HOG etc. These outputs were then compared with existing object templates, usually at multi scale levels, to detect and localize objects present in the image.
Two-Step Object Detection
Two-Step Object Detection involves algorithms that first identify bounding boxes which may potentially contain objects and then classify each bounding separately.
The first step requires a Region Proposal Network (RPNs), providing a number of regions which are then passed to common Deep Learning based classification architectures. From the hierarchical grouping algorithm in RCNNs (which are extremely slow) to using CNNs and ROI pooling in Fast RCNNs and anchors in Faster RCNNs (thus speeding up the pipeline and training end-to-end), a lot of different methods and variations have been provided to RPNs.
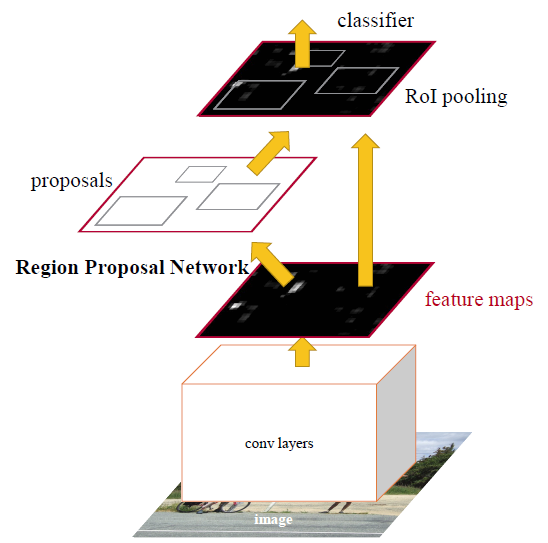
These algorithms are known to perform better than their one-step object detection counterparts, but are slower in comparison. With various improvements suggested over the years, the current bottleneck in the latency of Two-Step Object Detection networks is the RPN step.
One-Step Object Detection
With the need of real time object detection, many one-step object detection architectures have been proposed, like YOLO, YOLOv2, YOLOv3, SSD, RetinaNet etc which try to combine the detection and classification step.
One of the major accomplishments of these algorithms have been introducing the idea of ‘regressing’ the bounding box predictions. When every bounding box is represented easily with a few values (for example, xmin, xmax, ymin and ymax), it becomes easier to combine the detection and classification step and dramatically speed up the pipeline.
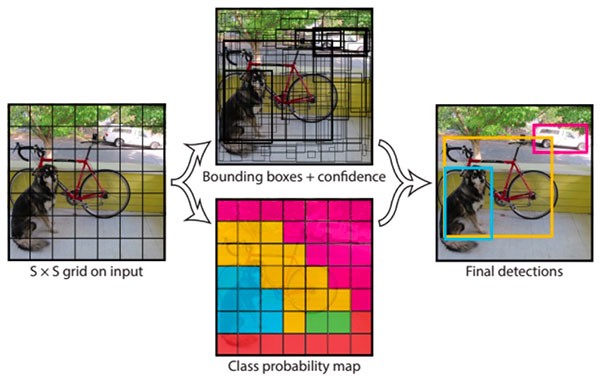
For example, YOLO divided the entire image into smaller grid boxes. For each grid cell, it predicts the class probabilities and the x and y coordinates of every bounding box which passes through that grid cell. This approch is kind of like the image based captcha where you select all smaller grids which contain the object.
These modifications allow one-step detectors to run faster and also work on a global level. However, since they do not work on every bounding box separately, this can cause them to perform worse in case of smaller objects or similar object in close vicinity. There have been multiple new architectures introduced to give more importance to lower level features too, thus trying to provide a balance.
Heatmap-based Object Detection
Heatmap-based object detection can be, in some sense, considered an extension of one-shot based Object Detection. While one-shot based object detection algorithms try to directly regress the bounding box coordinates (or offsets), heatmap-based object detection provides probability distribution of bounding box corners/center.
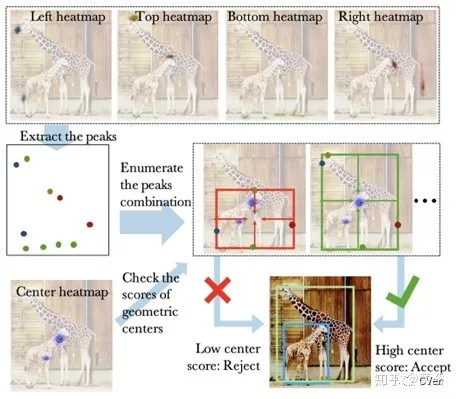
Based on the positioning of these corner/center peaks in the heatmaps, resulting bounding boxes are predicted. Since a different heatmap can be created for every class, this method also combines detection and classification. While heatmap-based object detection is currently leading new research, it is still not as fast as conventional one-shot object detection algorithms. This is due to the fact that these algorithms require more complex backbone architectures (CNNs) to get state-of-the-art accuracy.
Common metric for Object Detection
Intersection over Union (IoU), Average Precision (AP) and Average Recall (AR) are some of the common metrics used for object detection by the community.
Intersection over Union (IoU)
Bounding box prediction cannot be expected to be precise on the pixel level, and thus a metric needs to be defined for the extent of overlap between 2 bounding boxes.
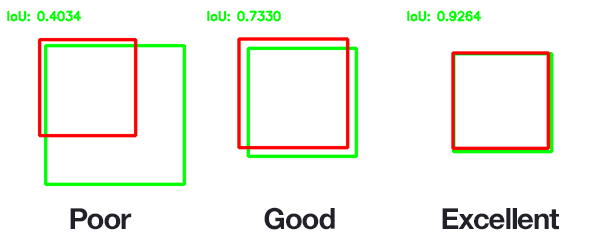
Intersection over Union does exactly what it says. It takes the area of intersection of the 2 bounding boxes involved and divide it with the area of their union. This provides a score, between 0 and 1, representing the quality of overlap between the 2 boxes. This bounding overlap can be visually seen in the Oscars image above.
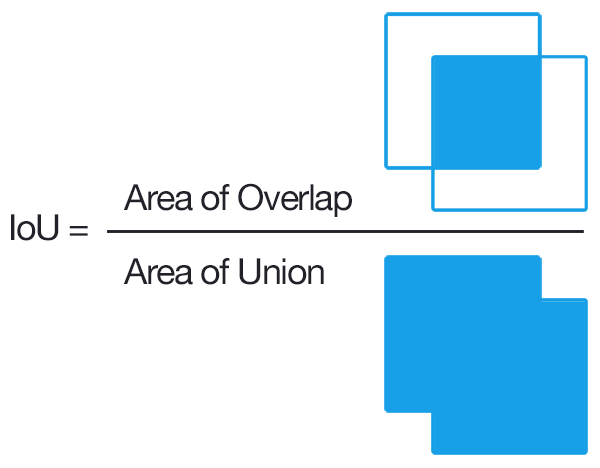
In Object Detection cases, the two bounding box would be the Predicted Bounding Box and the Ground Truth Bounding Box. So the higher IoU mean better algorithms is preforming
Average Precision (AP) and Average Recall (AR)
Precision meditates how accurate are our predictions while recall accounts for whether we are able to detect all objects present in the image or not.
Let’s start with the definition of precision and recall.
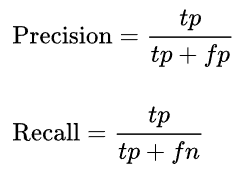
where tp = true positive, fp = false positive, fn = false negative. What are they? The table below should make things clear:
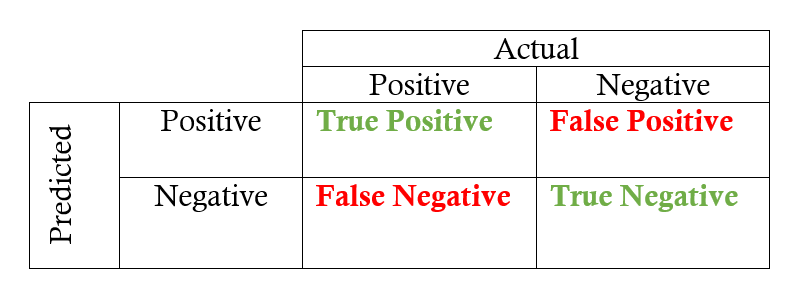
So basically precision is measuring the percentage of correct positive predictions among all positive cases in the ground truth; and recall is measuring the percentage of correct positive predictions among all predictions made. There is always a trade-off between the two metrics. Imagine if we label everything as positive, then recall will be 1 because we do not have false negatives, but precision will be horrible because only a small percentage of our positive predictions are actually correct. In the other extreme case, we can be very careful about the selection of positive prediction, so prediction will be very good, but we might have labelled many positive cases as negative and consequently lowered recall.
Conclusion
In this blog, we show you the basics about Object Detection, intricacies involved, metrics for precision, and trad-offs. We also show you different methods of Object Detection and how to evaluate Object Detection algorithms.
In the next blog, we will show you how we at Raft applied Object Detection on Aerial Imagery Object Detection problem.
Contact Us
If you’re interested in designing a Native App or Progressive Web App, our team of UX gurus have their fingers on the pulse of the mobile development community. Reach out to us at [email protected].


![Raft [R]DP Blog Post - Thumbnail Image](https://teamraft.com/wp-content/uploads/Raft-RDP-Blog-Post-Thumbnail-@2x.jpg)


